面向CUDA编程
面向CUDA编程
资料[1]
GPU硬件机制
CUDA编程模型基础
host:CPU及其内存
device:GPU及其内存
核心组件:流式多处理器SM

在物理机中包含多个SM,SM会划分Block执行任务。
SM的核心组件包括CUDA核心,共享内存,寄存器等,可以并发的执行数百个线程。
SM有多个基本执行单元线程束
在单个SM执行任务时,SM采用的是SIMT (Single-Instruction, Multiple-Thread,单指令多线程),基本的执行单元是线程束(warps)
SM采用SIMT架构,基本执行单元是32线程组成的线程束。
线程束(Warp)
同一线程束内所有线程特点:
- 同步执行相同指令
- 拥有独立寄存器状态和指令地址计数器
可因分支产生不同执行路径(线程束分化)
线程束分化会导致部分线程等待,降低执行效率
串行执行不同分支:SM会先执行条件满足的线程(例如进入 if 分支的线程),此时不满足条件的线程被临时禁用(masked out) 。执行完当前分支后,SM会返回分支点,再执行另一分支的指令(例如 else 分支),此时原分支的线程被禁用。
资源分配限制
SM为每个线程块分配共享内存
为每个线程分配独立寄存器资源
资源限制决定了SM能并发的线程块和线程束数量
性能优化关键点
- Block大小应设为32的倍数(匹配线程束的32线程基础单元)
- 尽量减少线程束分化(如避免过多分支判断)
正如jyy说过:计算机世界没有魔法,我们可以通过代码去测试检验他的线程束分化(这里是伪代码)
1 | |
CUDA程序
典型的CUDA程序的执行流程:
- 分配host内存,并进行数据初始化;
- 分配device内存,并从host将数据拷贝到device上;
- 调用CUDA的核函数在device上完成指定的运算;
- 将device上的运算结果拷贝到host上;
- 释放device和host上分配的内存。
三个函数限定词
由于GPU实际上是异构模型,所以需要区分host和device上的代码,在CUDA中是通过函数类型限定词开区别host和device上的函数,主要的三个函数类型限定词如下:
-
__global__:在device上执行,从host中调用(一些特定的GPU也可以从device上调用),返回类型必须是void,不支持可变参数参数,不能成为类成员函数。注意用__global__定义的kernel是异步的,这意味着host不会等待kernel执行完就执行下一步。 -
__device__:在device上执行,单仅可以从device中调用,不可以和__global__同时用。 -
__host__:在host上执行,仅可以从host上调用,一般省略不写,不可以和__global__同时用,但可和__device__,此时函数会在device和host都编译。
核函数
1 | |
注意事项:
- 核函数只能访问GPU内存
- 核函数不能使用变长参数
- 核函数不能使用静态变量
- 核函数不能使用函数指针
- 核函数具有异步性
CUDA内存模型详解
他们有一些性质:
- 同一个网格上的线程共享相同的全局内存空间
- 线程都是并行化运行(由于GPU的多核心特性,线程是轻量化的)
- 每一个线程可以通过(blockIdx,threadIdx)来唯一标识
- 一个block的线程是放在同一个流式多处理器(SM)上的,单个SM的资源有限,这导致线程块中的线程数是有限制的,现代GPUs的线程块可支持的线程数可达1024个。
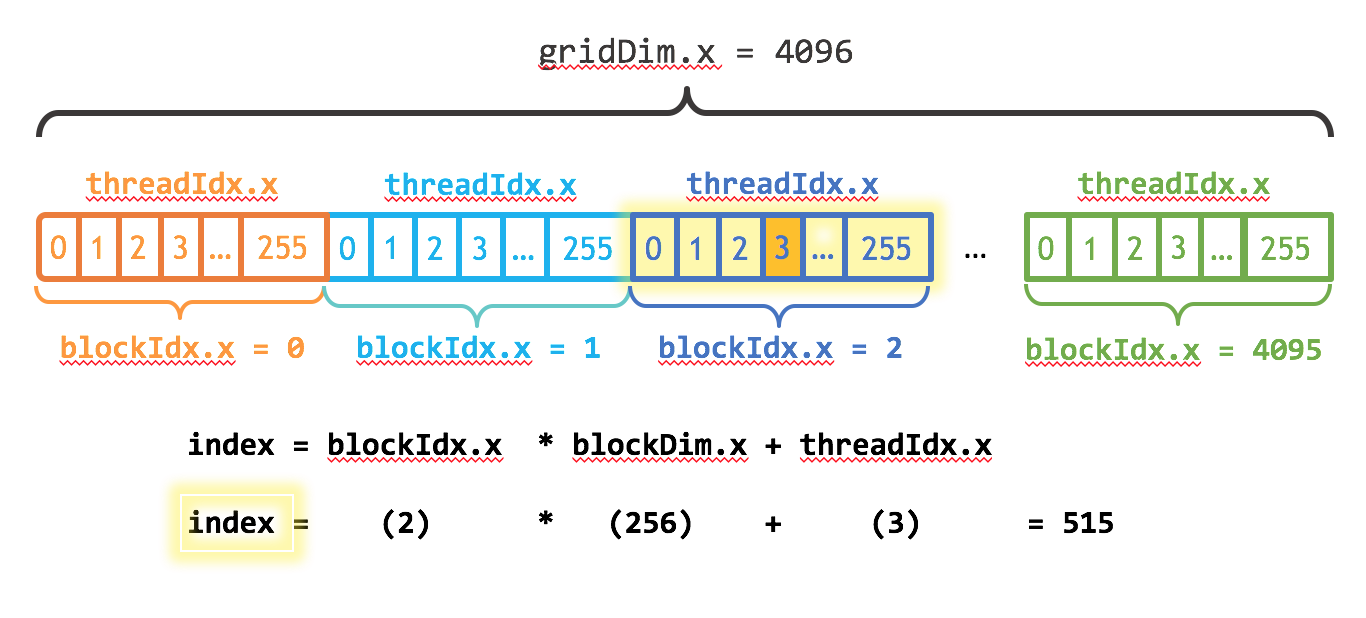
线程全局ID计算
在已知线程的内置变量blockDim和gridDim的情况下
对于一个2-dim的block $(D_x, D_y)$ ,线程 $(x, y)$ 的ID值为 $(x + y * D_x)$ ,如果是3-dim的block $(D_x, D_y, D_z)$ ,线程 $(x, y, z)$ 的ID值为 $(x + y * D_x + z * D_x * D_y)$ 。
CUDA的内存模型
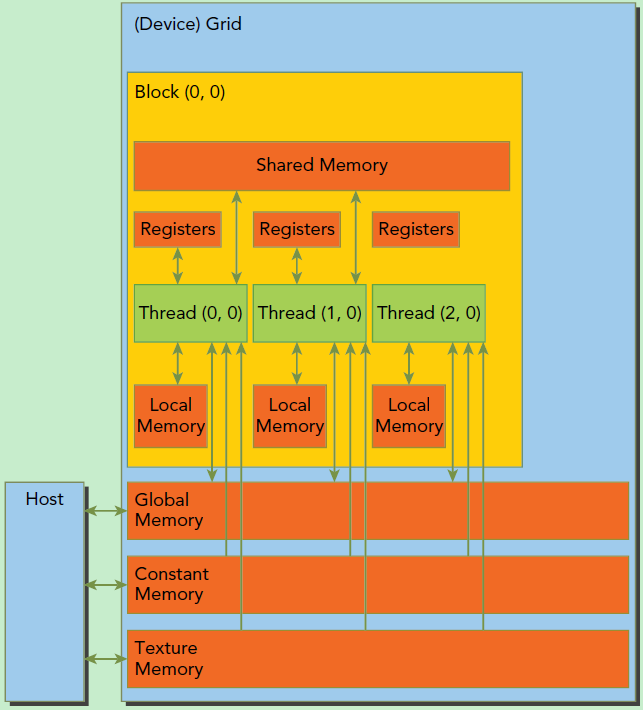
- 每个线程Thread有自己的私有本地内存
- 每个线程块Block有包含共享内存
- 所有的线程都可以访问全局内存
- 全局内存(Global Memory)
只读内存块:
常量内存(Constant Memory)
纹理内存(Texture Memory)
内存管理API
在device上分配内存的cudaMalloc函数
1 | |
负责host和device之间数据通信的cudaMemcpy函数
1 | |
上述由用户手动去控制内存分配容易出问题,于是在CUDA 6.0引入统一内存来避免这一麻烦
cudaMallocManaged函数分配托管内存
1 | |
在程序运行结束要用cudaDeviceSynchronize()函数保证device和host同步